

The idea of a virtual, computerized assistant that you can talk to conversationally isn’t anything new. Sci-fi visionaries have been dreaming of it for decades. What is new is that it’s finally possible. Through the rapid advancement of AI, you can download software to your PC right now that will let you configure your own chatbot and run it on your own computer, all without a subscription or token-based restrictions. The hardware requirements for doing this can be steep, but modern ASUS motherboards bring reasonable local AI chatbot performance within the reach of a wide range of users. Their secret weapon is a BIOS feature called ASUS AI Cache Boost, available with the combination of an ASUS 800 or 600 Series motherboard and an AMD Ryzen 9000 Series Granite Ridge CPU. Activating it engages a wide variety of optimizations that mitigate the performance hit that comes with oversaturating your graphics card’s VRAM, giving you a better experience when you’re running an LLM that doesn’t fit in GPU memory.
The potential performance uplift from AI Cache Boost can be game-changing. In testing scenarios where we used an LLM that required more VRAM than our test system could provide, we were able to increase chatbot performance by 15.12% just by activating AI Cache Boost. What’s more, when we overclocked system memory up to DDR5-8000 and bumped the Infinity Fabric Clock up to 2200MHz in addition to enabling AI Cache Boost, we were able to increase performance up to 29.13%. For many users, that uplift can prove to make the difference between a chatbot that’s a bit too sluggish for practical use and a chatbot that can produce words faster than we can read.
The challenges of running a local AI chatbot
Let’s take a step back and look at why smooth AI chatbot performance has remained tantalizingly out of reach for too many PC users. The trouble is that while it’s possible to run a local AI chatbot, most of us don’t have PC hardware capable of providing a great experience while doing so.

That’s because large language models, the tech behind AI chatbots, love large quantities of VRAM. The graphics cards at the very top of the NVIDIA 50 Series lineup, like the ROG Astral GeForce RTX 5090, can handle higher-parameter models thanks to their 32GB of GDDR7. But these top-shelf components aren’t within the budget of every PC builder, and even with one in your system, it’s not hard to find an LLM that will ask for even more VRAM than your card can provide.
Complicating the situation further is that most of us don’t want to devote all our computer’s resources to a chatbot: we want to run it alongside our usual applications so that we can leverage the unique capabilities of AI for research, productivity, gaming, creative work, and more. Ideally, a locally-run AI chatbot should only claim a slice of our graphics card’s VRAM, not the entire pie.
You do have options for this conundrum. One solution is to drop down to a lower-parameter model. A 7B (7 billion parameter) model only needs about 8GB of RAM and 4GB of storage. Hardware that meets those requirements won’t break the bank. But 7B models don’t typically have the flexibility and versatility needed to be compelling conversational companions. Different models are better at this than others, but many AI enthusiasts end up looking for ways to bump up to a higher parameter model.
What happens when an LLM needs more VRAM than your system can provide
Another option is to run a larger model anyway and take the performance hit that comes with saturating your GPU VRAM. When available GPU memory runs short while you’re running a larger LLM, part of the work gets offloaded to system memory instead. When this happens, the chatbot can’t run as efficiently, but it can still run if your system is sufficiently powerful.
The question in this scenario is whether the chatbot can run fast enough. The measuring stick that many use here is tokens per second. As long as a chatbot can produce words faster than we can read them, it’s generally considered fast enough to feel like a conversation. Assuming that one token equals one word in a chatbot’s response to a query (which is true most of the time), the minimum is about five tokens per second. That equates to about 300 words per minute, which is in the upper range of how many words an average adult can read per minute. Many folks prefer something higher, as they often skim through a chatbot’s responses rather than read each word individually and carefully.
Why AI Cache Boost can help in this scenario, and how to activate it
Whenever you’re running an AI chatbot, your PC’s computational resources are already engaged. Even when you’re using an LLM that fits entirely in the VRAM you have available, your GPU will at times decide to make use of CPU processing power for this data, and when it does, the performance of your CPU cache and DRAM comes into play.
When your VRAM gets saturated, on the other hand, the full computational pathway from your GPU to CPU to I/O die to VRAM gets put to work. Anything that you can do to optimize this path can have a measurable impact in this scenario — and that’s exactly what happens when you enable AI Cache Boost. When you activate this feature, it applies a wide range of optimizations, including overlocking the Infinity Fabric clock (FCLK) to 2100 MHz. Boosting FCLK is an important piece of the puzzle here, since it boosts the bandwidth of data transfers between CPU cores, cache, and memory, and those transfers matter a lot when you’re working with an LLM that doesn’t fit in your VRAM.
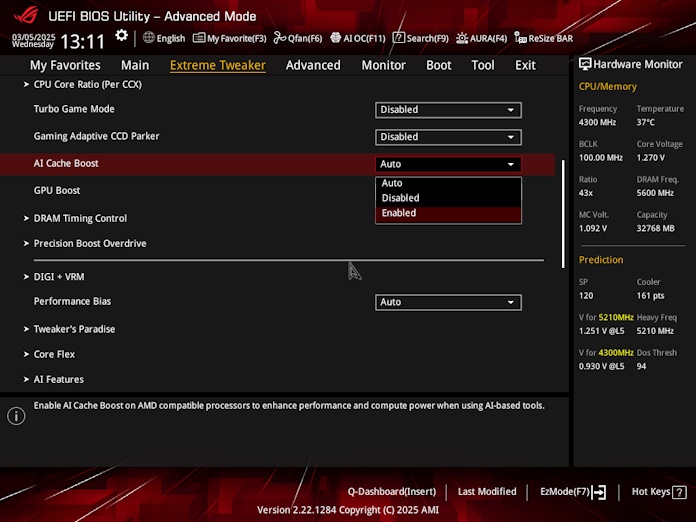
To access AI Cache Boost, you’ll need an ASUS AMD 800 or 600 Series motherboard and an AMD Ryzen 9000 Series Granite Ridge CPU. Open the UEFI BIOS utility and navigate to the Extreme Tweaker tab. Toggle AI Cache Boost to “Enabled” and you’re off to the races.
The performance uplift of AI Cache Boost
To put AI Cache Boost to the test, we constructed a scenario that fits the needs and hardware of many PC users today. We built a test PC featuring the ROG Crosshair X870E Hero, an AMD Ryzen 7 9800X3D, and 32GB of DDR5 — all popular and relatively common consumer-grade components. We tested a small variety of graphics cards equipped with 16GB of GDDR7, a requirement that’s accessible in 2025, as cards that meet that bar can be had for less than $500.
In our tests, we tasked a 32B LLM to write a story in 100 words. Even with 4-bit quantization, the LLM had no business fitting into available VRAM, putting the rest of the system to work. With default settings, we observed up to 6.35 tokens per second. That’s not terrible, but it could be much better. A quick trip into BIOS to enable AI Cache Boost increased performance by up to 7.31 tokens per second, a 15.12% increase.
Even more performance with optimized DRAM and FCLK
Intriguingly, we also found that we could bump up tokens per second significantly through higher-performance memory. The conventional wisdom with the AMD Ryzen AM5 platform is that the sweet spot for memory is DDR5-6000 or DDR5-6400, after which point you’ll see diminishing returns. But in this test scenario, we uncovered a very welcome performance boost by opting for a much faster memory kit.

By enabling the EXPO profile of a DDR5-6000 kit alongside AI Cache Boost, we were able to boost tokens per second up to 21.73%. But the ROG Crosshair X870E Hero can run much faster DRAM kits than that. If you’re looking for a smooth experience with bleeding-edge memory kits, motherboards like this one are capable of some truly dazzling memory configurations thanks to NitroPath DRAM technology. When we popped a DDR5-8000 kit into our test rig and enabled its EXPO profile along with AI Cache Boost, we were able to boost LLM performance up to 24.57%.
A final note for enthusiasts willing to push their systems even further. With AI Cache Boost, we apply a relatively conservative FCLK overclock. You might feel comfortable boosting things even farther, and if you do so, our testing suggests that you’ll get a measurable improvement in a scenario where an LLM saturates available VRAM. After activating AI Cache Boost, toggling the EXPO profile of a DDR5-8000 kit, and bumping FCLK up to 2200MHz, we achieved up to 8.2 tokens per second in our test. That’s a 29.13% increase over default settings.
Why this all matters
Too many PC users are tantalizingly close yet frustratingly far away from the long-held dream of having an intelligent chatbot running on their PCs. For decades, we’ve dreamed of having access to an AI that’s not only capable of handling simple queries, but equipped for complex reasoning and everyday conversation.
Cloud-based subscriptions can offer this experience, but only to a certain extent. These services are still limited by token systems, and they don’t offer the privacy and security of a locally run app. Instead, many of us would much prefer to run an AI chatbot on our own hardware. After all, that’s the mindset that launched the PC building community in the first place. We like reading about stuff that can run in data centers and supercomputing clusters. But what gets us truly excited is the ability to run advanced applications on our own terms on our own machines.
ASUS AI Cache Boost does just that when it comes to running a chatbot. Offering up to a 15.12% increase on its own and up to 29.13% more AI performance alongside memory optimizations and an FCLK overclock, AI Cache Boost mitigates the performance penalty of running an LLM that saturates available video memory. Through AI Cache Boost, you might be able to run your preferred model at acceptable tokens per second without giving your entire pool of VRAM to one application. It could also allow you to operate an LLM with an even higher parameter count for a much-improved experience.

And it’s all available on mainstream hardware. Our testing rig for AI Cache Boost boasts some powerful components, to be sure, but we by no means selected the most premium gear in our product stack. The results we achieved were accomplished with one of the most popular CPUs on the market today installed on a mainstream motherboard. The graphics cards we used weren’t entry-level, but you have plenty of options in 2025 if you’re shopping for a graphics card with 16GB of VRAM. The 2x16GB DDR5-6000 memory kit we used is eminently affordable, and you wouldn’t even have to spend all that much more to acquire the higher-end 2x16GB DDR5-8000 kit.
All this means that the idea of operating an intelligent virtual assistant capable of analysis and conversation is no longer a dream. It’s a reality. You can do it today on mainstream hardware, using ASUS AI Cache Boost to take the experience from tolerable to enjoyable.
To take advantage of ASUS AI Cache Boost, you’ll need an AMD Ryzen 9000 Series Granite Ridge CPU and one of our AMD 800 or 600 Series motherboards. Click here to learn more about our X870 boards, and here to browse our B850 selection.